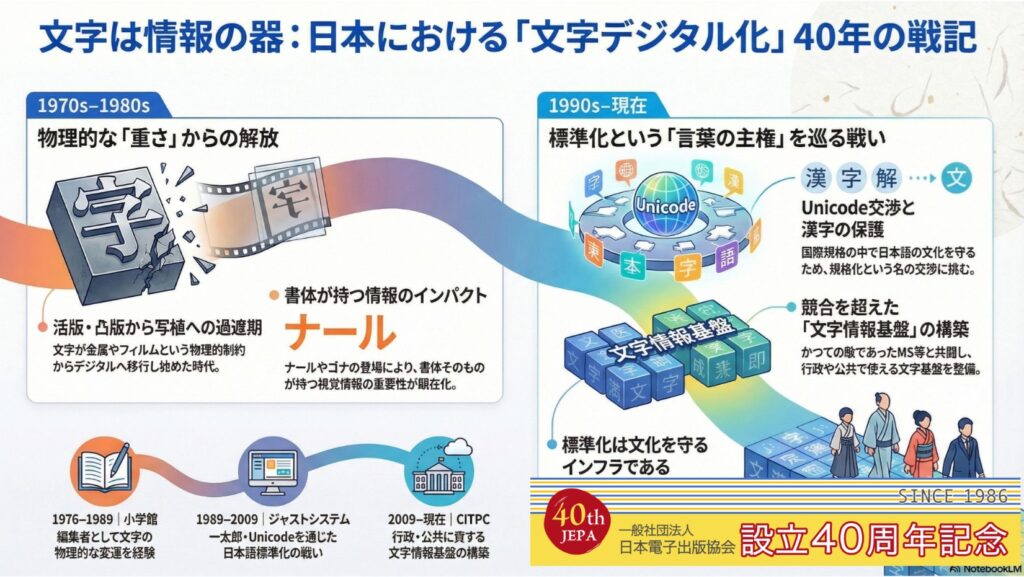
2026年4月20日 小林龍生氏:文字は情報の器ーードラえもん担当編集者の波乱万丈戦記
公開⽇:
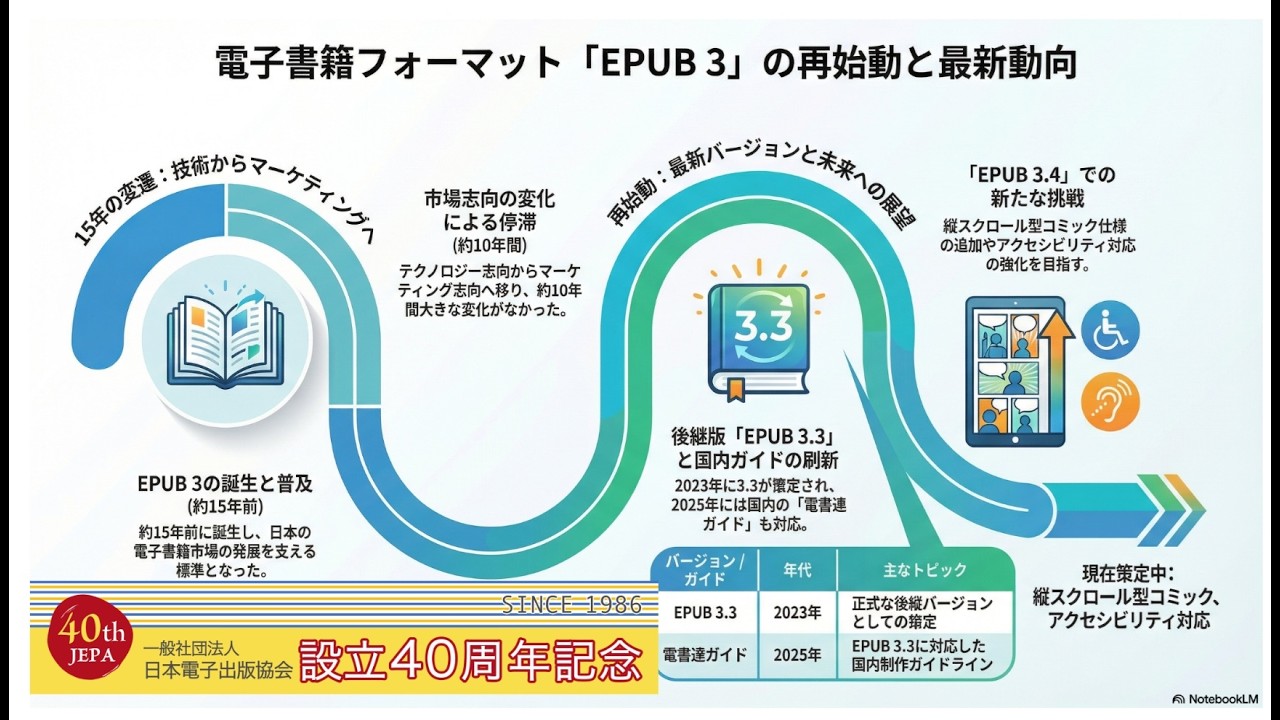
1. イントロダクション 挨拶とJEPA40周年への祝辞 「3つの時代」の提示: 1976~1989:小学館(編集者として文字に触れる) 1989~2009:ジャストシステ...

公開⽇:
1. イントロダクション 挨拶とJEPA40周年への祝辞 「3つの時代」の提示: 1976~1989:小学館(編集者として文字に触れる) 1989~2009:ジャストシステ...
公開⽇:
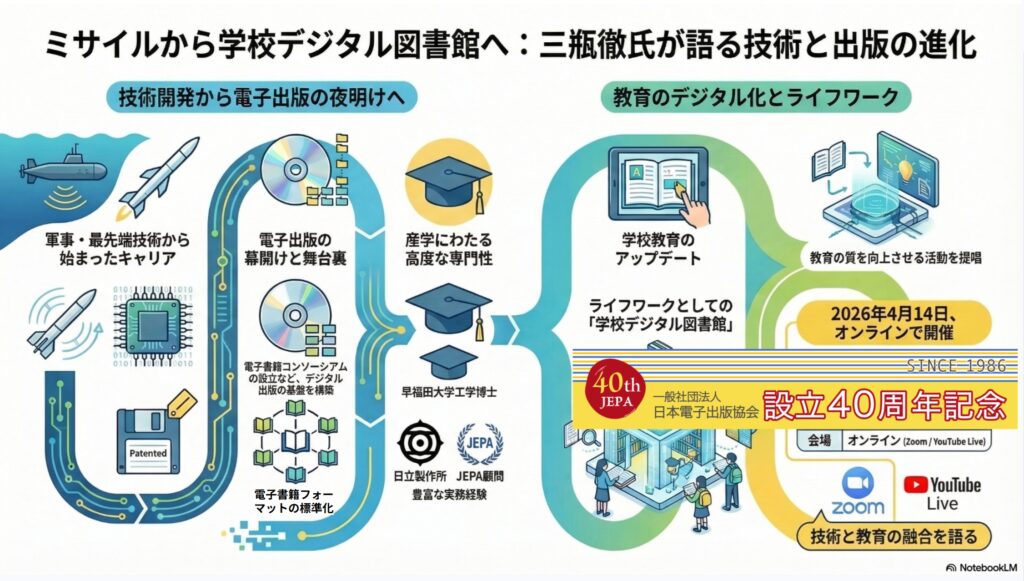
1.自己紹介 ・潜水艦用パッシブソナー ・地対空ミサイル・ナイキ ・パワーMOSFETと西沢潤一さんのSIT(静電誘導トランジスタ)論争 ・音声目覚まし時計付きラジオを持ってアメリカ議会図書館...

公開⽇:
日本のマンガ産業は、この20年で大きく構造を変えてきました。とりわけ電子コミックの普及は、出版市場のビジネスモデルを大きく変え、現在ではマンガの多くが電子書店を通じて読まれる時代となっています。 本...
公開⽇:
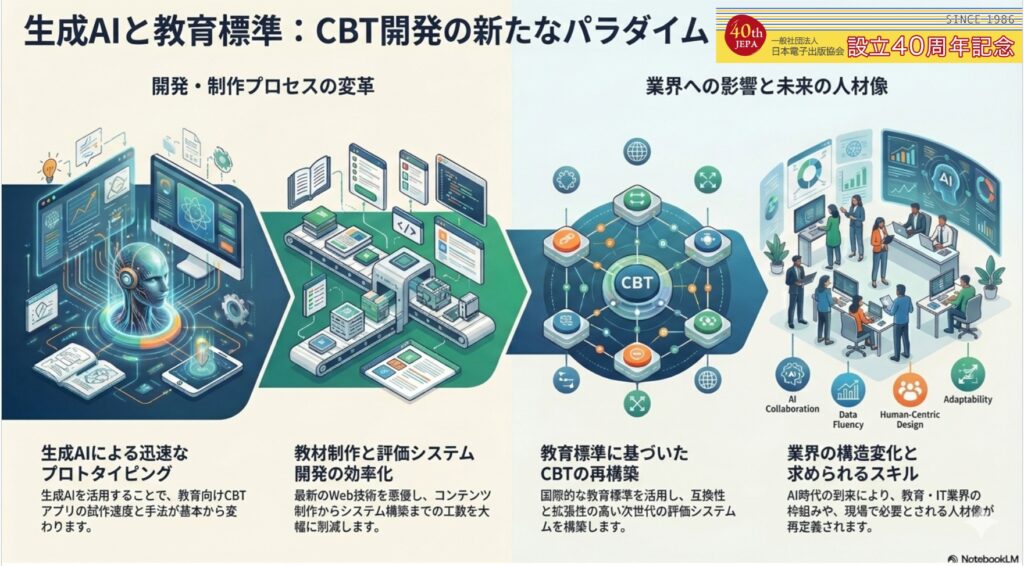
生成AIの急速な進化により、アプリケーション開発の体制や手法は大きく変わりつつあります。本セミナーでは、生成AIを活用して教育向けCBT(Computer Based Testing)Webアプリ(*...