『紙の書籍をデジタル化して電子書籍(電子出版)の世界を作る』という掛け声からすでに30年ほど過ぎようとしています。当時は『電子なんてありえない、紙こそ命!』といったことがささやかれておりましたが、近年ではコロナ禍の影響もあり、電子出版が生活の中に溶け込んでいます。最近ではオーディオブックの活用者も増え、ますますデジタル化が進んでいます。出版業界において、出版DX(デジタルトランスフォーメーション)への取り組みを頑張ってきた成果と言えるのではないでしょうか。
同じ現象が、研究開発の世界でも起きています。ここ数年で「データ駆動型科学」という、いわゆるビッグデータを利用して、新しいデータ(価値)を発見する手法が進展しています。この手法は、仮説をもとに検証する研究に対して、“仮説を立てず”に収集したビッグデータを分析して“新しいデータ”を創出するものです。
しかし、この「データ駆動型科学」で問題になることがあります。それは「データの品質」です。確かにデータは多くあった方がいろいろな分析ができるようになりますが、一方で、データが間違っていたり、改竄されていたりした場合は、分析した結果は、研究として価値がなく、信ぴょう性が疑われてしまう結果になってしまいます。
文部科学省では、研究活動における不正行為への対応等に関するガイドライン(PDF)を公表しています。そのガイドラインによると、「対象とする不正行為は、故意又は研究者としてわきまえるべき基本的な注意義務を著しく怠ったことによる、投稿論文など発表された研究成果の中に示されたデータや調査結果等の捏造、改ざん及び盗用である(「特定不正行為」という)」と述べており、以下のように定義されています。
【捏造】存在しないデータ、研究結果等を作成すること。
【改ざん】研究資料・機器・過程を変更する操作を行い、データ、研究活動によって得られた結果等を真正でないものに加工すること。
【盗用】他の研究者のアイディア、分析・解析方法、データ、研究結果、論文又は用語を当該研究者の了解又は適切な表示なく流用すること。
電子出版でのデータの品質でも同様なことが言えると思っています。電子出版では、データ自身、すなわちコンテンツ自身の品質が最も重要視されており、このコンテンツの品質が、出版の価値につながっているためです。このコンテンツ自身の品質の考えが、データ管理の中でも重要視されてきていることは、デジタル化を推進する世界では良い傾向となっていると思っています。
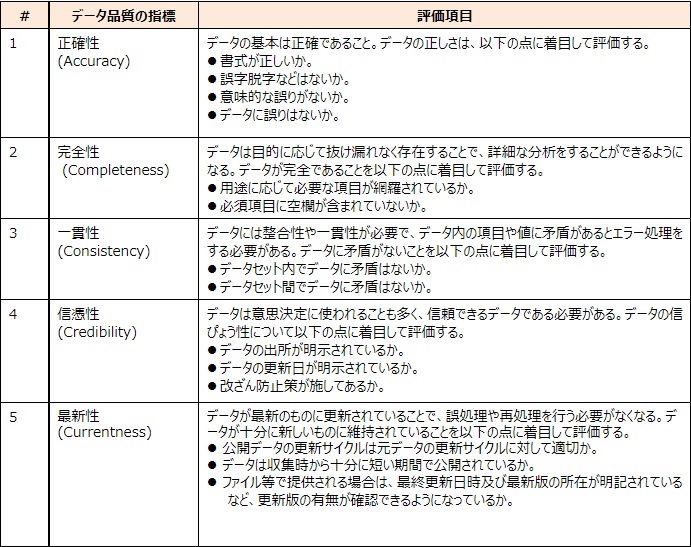
さて、データ自体の品質を確保するために、データ品質に関する指標として、データ品質管理ガイドブック:政府相互運用性フレームワーク(GIF)が公表されています。データ品質管理ガイドブックでは、データ自体の品質を考えるための指標として、ISO/IEC25012に着目しています。このISO/IEC25012では、データ品質の指標として15つの指標を示しています。私は、その中でデータそのもの、すなわちコンテンツ自身の品質の特性を持つ指標は、以下の5つであると考えており、データの品質をチェックする際には、まずはこの5点に着目する必要があるのではないかと思っています。ここではこの5つだけをご紹介します。
また、この15の指標の中に、データを流通させるための指標があり、上記以外に“アクセシビリティ”、“理解性”、“可用性”、“移植性”の4つが必要と考えます。この4つの指標は、国際的な学術コミュニケーションのための国際会議FORCE11が、策定・公開する研究データの公開時に関するガイドラインのFAIR原則でも提唱されており、データ共有の原則として広まっています。
欧米をはじめ、日本でも、いくつかの研究資金を提供する機関が、研究データを扱う際の基準として「FAIR原則に従うこと」をガイドラインで推奨しています。なお、FAIRとは、Findable(見つけられる)、Accessible(アクセスできる)、Interoperable(相互運用できる)、Reusable(再利用できる)のそれぞれの頭文字を取った略語です。
このように、出版でいうコンテンツの品質が、研究分野でも、とても重要な位置を占めつつある現状は、これまで電子出版を進めてきたJEPAにとって、ある意味うれしい事象ではないでしょうか。